서론
어느 날, 나는 숫자 1,000,000을 하나씩 세고 싶어졌다.
그러나 for-loop로 1부터 1,000,000까지 하나씩 세는 것은 비효율적이라고 판단해 멀티 스레딩을 이용하여 1부터 250,000까지 세는 스레드를 네 개 만들어서 1,000,000을 세어보기로 하였다.
Lock이 없을 때
코드
코드는 다음과 같다.
import threading
import time
result = 0
def count(num):
# result에 1씩 더하는 작업을 num회 실시
global result
for _ in range(num):
result += 1
thread_1 = threading.Thread(target = count, args = (250000,))
thread_2 = threading.Thread(target = count, args = (250000,))
thread_3 = threading.Thread(target = count, args = (250000,))
thread_4 = threading.Thread(target = count, args = (250000,))
thread_1.start()
thread_2.start()
thread_3.start()
thread_4.start()
thread_1.join()
print("thread_1 counting over")
thread_2.join()
print("thread_2 counting over")
thread_3.join()
print("thread_3 counting over")
thread_4.join()
print("thread_4 counting over")
print(result)count 함수는 전역(global) 변수엔 result에 1씩 더하는 작업을 num번 실시하는 함수이다.
이 함수를 스레드화하여 총 네개의 스레드를 만들었으며,
각 스레드는 종료 후에 "thread_{i} counting over"를 출력하여 최종적으로 result의 값을 확인한다.
결과

하나의 스레드가 총 250,000번 1을 더하며, 총 4개의 스레드가 작업을 했으므로 예상되는 수치는 250,000 * 4 = 1,000,000번이다. 그러나 결과를 보면 934,198 번으로 약 7만 번의 계산이 누락되었다는 것을 확인할 수 있다.
계산이 누락된 이유?
전역 변수에 숫자를 1 더하는 과정은 다음과 같다.
- 전역 변수
result의 값이 레지스터(register)에 저장된다. - 해당 레지스터의 값을 1 증가시킨다.
result에 증가시킨 값을 저장한다.
일반적으로 생각되는 연산은 다음과 같다. 편의를 위해 두 가지의 스레드만 존재한다고 해보자.
thread 1이result의 값을 레지스터에 저장한다.thread 1의 레지스터의 값을 1 증가시킨다.result에 증가시킨 값을 저장한다.thread 2가result의 값을 레지스터에 저장한다.thread 2의 레지스터의 값을 1 증가시킨다.result에 증가시킨 값을 저장한다.
해당 순서대로 진행된다면, thread 2가 이미 thread 1에 의해 1 증가된 result 값을 가져와 작업하므로 result의 결과는 2가 된다.
그러나 다음과 같은 순서대로 작업이 진행될 수 있다. 이는 스레드의 실행 순서를 특정 지을 수 없기 때문이다.
thread 1이result의 값을 레지스터에 저장한다.thread 2가result의 값을 레지스터에 저장한다.thread 1의 레지스터의 값을 1 증가시킨다.thread 2의 레지스터의 값을 1 증가시킨다.result에 증가시킨 값을 저장한다.result에 증가시킨 값을 저장한다.
이 경우, thread 1이 1을 더하는 작업을 마무리 하기도 전에 thread 2가 result의 값을 참조하기 때문에 두 스레드 모두 0에 1을 더하는 작업을 하게 되며, 최종적으로 result는 2가 아닌 1이 된다.
이러한 문제를 경쟁 상태 혹은 경쟁 조건(race condition)라고 한다.
경쟁 상태란, 둘 이상의 입력 또는 조작의 타이밍이나 순서 등이 결과값에 영향을 줄 수 있는 상태를 말한다
이를 해결하기 위해서는 공유 자원에 접근하는 방식에 제약을 걸 필요가 있다. 그리고 본 문서에서는 제약 조건으로 Lock을 사용한다.
Lock
lock은 "자물쇠로 잠그다"라는 의미를 가지고 있다.
특정 스레드가 특정 변수를 바탕으로 작업을 할 때 해당 변수를 잠그는 것으로, 다른 스레드가 해당 변수에 접근하지 못 하도록 제한하는 것이다.
즉, thread 1이 result에 lock을 건 상태로 작업을 하고 있다면, thread 2는 result에 접근할 수 없다.
파이썬에서의 lock은 threading 라이브러리 내의 Lock 객체를 통해 구현할 수 있다. 구체적으로, Lock.acquire() 을 통해 lock을 획득 할 수 있으며, Lock.release()을 통해 lock을 해제할 수 있다.
코드
result = 0
thread_lock = threading.Lock() # Lock Instance 생성
def count(num):
# result에 1씩 더하는 작업을 num회 실시
thread_lock.acquire() # lock을 걸어 줌
global result
for _ in range(num):
result += 1
thread_lock.release() # lock을 해제함thread_lock이라는 lock instance를 생성하였으며, count 함수에 진입할 때 lock을 걸고, 탈출할 때 lock을 해제하였다.
결과

정상적으로 1,000,000이 출력되는 것을 확인할 수 있다.
여담 1. lock이 걸리는 위치
lock을 어디에 걸고 어디서 해제하냐에 따라 스레드가 제한하는 변수가 달라질 것이라고 생각한다.
따라서 전역 변수를 두 개를 선언하여 lock의 위치에 따른 출력 값의 변화를 실험해보았다.
경우 1
result_a = 0
result_b = 0
thread_lock = threading.Lock() # Lock Instance 생성
def count(num):
# result에 1씩 더하는 작업을 num회 실시
global result_a
global result_b
thread_lock.acquire() # lock을 걸어 줌
for _ in range(num):
result_a += 1
for _ in range(num):
result_b += 1
thread_lock.release() # lock을 해제함경우 1은 두 개의 for-loop 앞 뒤로 lock을 걸고 해제하는 경우이다.

결과적으로는 두 개의 변수 모두 정상적으로 1,000,000이 찍힌 것을 확인할 수 있었다.
경우 2
def count(num):
# result에 1씩 더하는 작업을 num회 실시
global result_a
global result_b
for _ in range(num):
result_a += 1
thread_lock.acquire() # lock을 걸어 줌
for _ in range(num):
result_b += 1
thread_lock.release() # lock을 해제함경우 2는 result_a에는 락을 걸지 않고, result_b에만 락을 걸어주는 경우이다.

예상했던 대로, result_a는 약 8000번의 덧셈의 누락된 것에 반해, result_b는 정상적으로 출력됨을 확인할 수 있다.
경우 3
def count(num):
# result에 1씩 더하는 작업을 num회 실시
thread_lock.acquire() # lock을 걸어 줌
global result_a
global result_b
for _ in range(num):
result_a += 1
thread_lock.release() # lock을 해제함
for _ in range(num):
result_b += 1경우 3은 result_a에만 락을 걸고, result_b에는 락을 걸지 않았다.
그러나 result_b가 전역변수라는 것을 알려주는 global result_b가 lock을 건 이후에 실행될 것이다.
그렇다면 result_b에는 다른 스레드는 접근할 수 없을까?

아닌 것 같다. global {variable}은 lock에 있어 큰 영향을 미치지는 못하는 것 같다.
경우 4
import threading
import time
result = 0
thread_lock = threading.Lock() # Lock Instance 생성
def count(num):
# result에 1씩 더하는 작업을 num회 실시
thread_lock.acquire() # lock을 걸어 줌
global result
for _ in range(num):
result += 1
thread_lock.release() # lock을 해제함
for _ in range(num):
result -= 1경우 4는 조금 더 특이한 경우이다. count 함수를 약간 변형했는데, num 회의 반복으로 1씩 더하고, 다시 num 회의 반복으로 1씩 뺀다.
그러나 덧셈을 하는 동안에는 lock을 걸어주었고, 뺄셈을 하는 동안에는 lock을 해제해주었다. 과연 결과가 어떻게 나올까?
덧셈을 하는 동안에는 다른 스레드가 접근할 수 없기 때문에 동일한 전역 변수에 덧셈을 하는 경우가 발생하지 않아 온전히 1,000,000을 더하고, 뺄셈을 하는 동안에는 다른 스레드가 접근할 수 있기 때문에 동일한 전역 변수에 뺄셈을 하는 경우가 발생하여 온전히 1,000,000을 빼지 못할 것이라고 판단했다.
즉, 결과적으로 0보다 큰 수가 나올 것이라 생각한다.
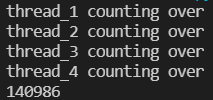
예상한 대로 0보다 큰 수가 나온 것을 확인할 수 있다.

뺄셈에만 lock을 걸었을 때에는 0보다 작은 수가 나옴을 확인할 수 있다.
여담 2. 하나의 변수, 두 개의 Lock
하나의 변수에 두 개의 lock을 걸어보자.
경우 1
thread_lock_a = threading.Lock() # Lock Instance 생성
thread_lock_b = threading.Lock() # Lock Instance 생성
def count(num):
# result에 1씩 더하는 작업을 num회 실시
global result
thread_lock_a.acquire() # lock을 걸어 줌
thread_lock_b.acquire() # lock을 걸어 줌
for _ in range(num):
result += 1
thread_lock_a.release() # lock을 해제함
thread_lock_b.release() # lock을 해제함경우 1은 같은 작업에 대해 lock을 두 개 걸고, 둘 다 해제하는 방식으로 구현하였다.
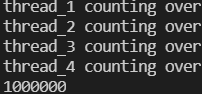
결론적으로 lock을 하나 거는 것과 큰 차이는 없었다. 그러나 lock 하나를 더 관리해야 하므로 관리 측면에서 비효율적일 것으로 판단하였다.
경우 2
import threading
import time
result = 0
thread_lock_a = threading.Lock() # Lock Instance 생성
thread_lock_b = threading.Lock() # Lock Instance 생성
def count(num):
# result에 1씩 더하는 작업을 num회 실시
global result
thread_lock_a.acquire() # lock을 걸어 줌
thread_lock_b.acquire() # lock을 걸어 줌
for _ in range(num):
result += 1
print(result)
thread_lock_a.release() # lock을 해제함
thread_1 = threading.Thread(target = count, args = (2500,))
thread_2 = threading.Thread(target = count, args = (2500,))
thread_3 = threading.Thread(target = count, args = (2500,))
thread_4 = threading.Thread(target = count, args = (2500,))
thread_1.start()
thread_2.start()
thread_3.start()
thread_4.start()
thread_1.join()
print("thread_1 counting over")
thread_2.join()
print("thread_2 counting over")
thread_3.join()
print("thread_3 counting over")
thread_4.join()
print("thread_4 counting over")
print(result)경우 2는 두 개의 락을 걸고, 하나만 해제해보았다. 그리고 연산 횟수를 편의상 2,500번으로 수정하였다.

우선 thread_1은 result에 대해 권한이 있기 때문에 정상적으로 2500번의 연산을 수행한다.
그러나thread_2는 result에 대해 권한이 없는데, 아직 lock_b가 걸려있는 상태기 때문이다. 따라서 접근할 수 없다.
이후 thread_2.join()함수는 thread_2가 종료될 때까지 대기하는데, thread_2는 result에 대해 권한이 없기 때문에 권한을 획득하기 전까지 종료될 수 없으며, 따라서 코드는 교착상태에 빠져 영원히 끝나지 않는다.
이를 데드락(Dead Lock)이라고 할 수 있는가?
데드락이란 두 개 이상의 작업이 서로 상대방의 작업이 끝나기를 대기하고 있는 상태이다.
그러나 lock_b를 해제하는 조건이 애초에 설정되어있지 않기 때문에 이를 상호 대기 상태라고 볼 수 있을지는 잘 모르겠다. (지극히 개인적인 의견입니다.)
참조
'개인 공부 > 파이썬' 카테고리의 다른 글
| [FastAPI] Mounting으로 FastAPI 기본 경로 설정하기 (0) | 2023.03.14 |
|---|---|
| [FASTAPI] FastAPI server가 시작될 때 인공지능 모델 load하기 (0) | 2023.03.14 |
| [Python] 멀티 스레드 - 4 (Dead Lock) (0) | 2022.12.23 |
| [Python] 멀티 스레드 - 2 (데몬 스레드) (0) | 2022.12.23 |
| [Python] 멀티 스레드 - 1 (0) | 2022.12.23 |